
How to Learn Behaviors
When it comes to learning a behavior, there are two fundamental approaches: 1. Copying others (imitation learning) or 2. Learning from rewards and punishments (reinforcement learning). Both methods have their strengths and limitations, and understanding their differences can help us choose the right approach depending on our objectives.
Imitation Learning
Imitation learning (IL) is a technique where an agent learns by mimicking expert behavior. The agent is provided with demonstrations from a human or an expert AI and learns to map observed states to actions without necessarily understanding why (or if) those actions are optimal.
A common example of imitation learning is behavior cloning, where an agent is trained on a dataset of state-action pairs collected from expert demonstrations. Since IL does not rely on a reward system, it can be an efficient way to teach an agent without worrying about things like: sparse rewards, credit assignment, exploration vs exploitation, etc.
There is an underlying assumption though, that the behavior being “cloned” is good. Later in the blog, we will explore what happens when this assumption does not hold true.
Reinforcement Learning
Reinforcement learning (RL), unlike imitation learning, does not merely copy behavior but rather learns how to make decisions through reward feedback. The goal is to learn the behavior that maximizes cumulative return.
Policy vs Value Function
+
In reinforcement learning, there are two main paradigms for learning optimal behavior: policy-based and value-based methods.
A policy defines the agent’s behavior by mapping states to actions directly π(s) → a. In policy-based methods, the goal is to optimize this mapping directly to maximize expected returns.
A value function, on the other hand, estimates how good it is to be in a certain state V(s) or how good it is to take a certain action from a state Q(s, a). Value-based methods focus on learning these estimates and derive the policy indirectly by selecting actions that maximize the value.
Some algorithms combine both approaches, like Actor-Critic methods, where the “actor” is the policy and the “critic” is the value function evaluating the actions.
Once enough experience has been gathered, RL has the potential to train agents that can outperform policies learned by human demonstrations. However, RL is data-hungry and computationally expensive, as the agent must evaluate numerous scenarios before converging on an effective policy.
Online vs Offline Reinforcement Learning
+
Online RL refers to algorithms that learn while continuously interacting with the environment. The agent collects fresh data, updates its policy, and refines its strategy in real-time. This approach enables ongoing adaptation but may require extensive exploration, which could be unsafe or expensive in some domains.
Offline RL, on the other hand, trains solely on a fixed dataset collected beforehand. It avoids the risks of live interactions but can struggle when the training data lacks diversity or doesn’t cover critical parts of the environment, leading to poor generalization.
Comparison: Flappy Bird Experiment
To better understand the differences between these approaches, let’s consider a simple game: Flappy Bird. The distinction is apparent when the expert demonstration diverges from the set of actions which would maximize the cumulative return.

In the visual above, the agent can copy what the “expert” human showed it (which would result in a death), or it can follow the path that gives it the most reward (going through the pipes).
In the following sections, we will conduct a little experiment to show how the difference manifests during training. We randomly initialize a feedforward neural network, and inspect the loss landscape for a couple weights in the network.
What is a Loss Landscape?
+
A loss function quantifies how far a model’s output is from the desired outcomes - it acts as a guide for improving performance. Whether you’re training a model to classify images, predict stock prices, or control an agent’s actions, the loss function provides a numerical value that reflects how “wrong” or “inaccurate” the model is. This numerical value is either referred to as the loss or error - we will use “loss” throughout this blog.
The loss function for IL could tell us the magnitude of divergence between the expert’s actions and the agent’s actions. While the loss function for RL could tell us how good or bad it was to take an action in a particular state.
The objective in most machine learning problems is to minimize this loss, helping the model become more accurate or effective over time. The loss landscape is a conceptual map that shows how the loss changes as we tweak the model’s parameters.
Note: The same neural network is used throughout all the experiments.
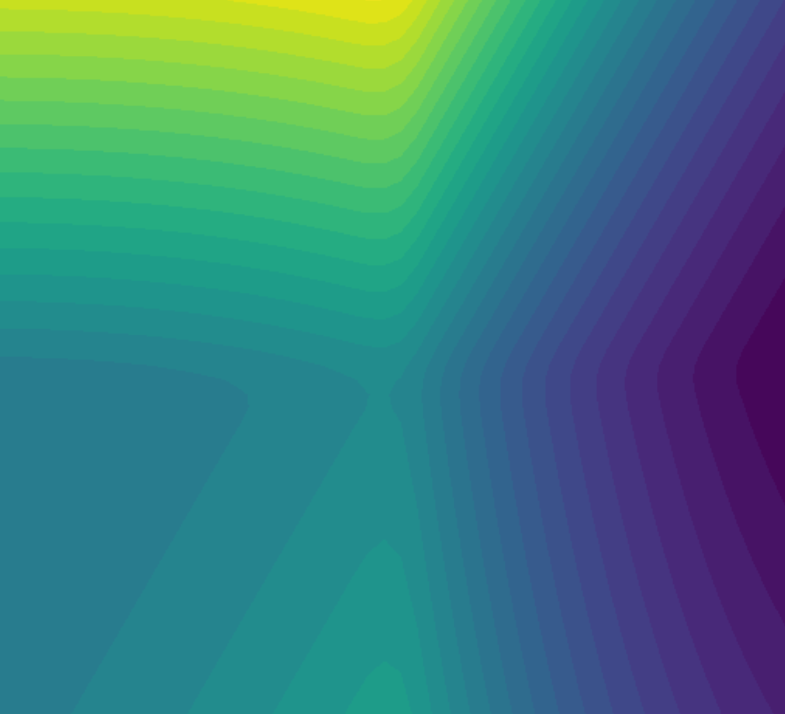
A Poor Gameplay Session
For the first part of the experiment, we collected data where we intentionally died right away. We see something very interesting - the loss landscape looks inverted when comparing the loss functions for IL vs RL.
Imitation Learning
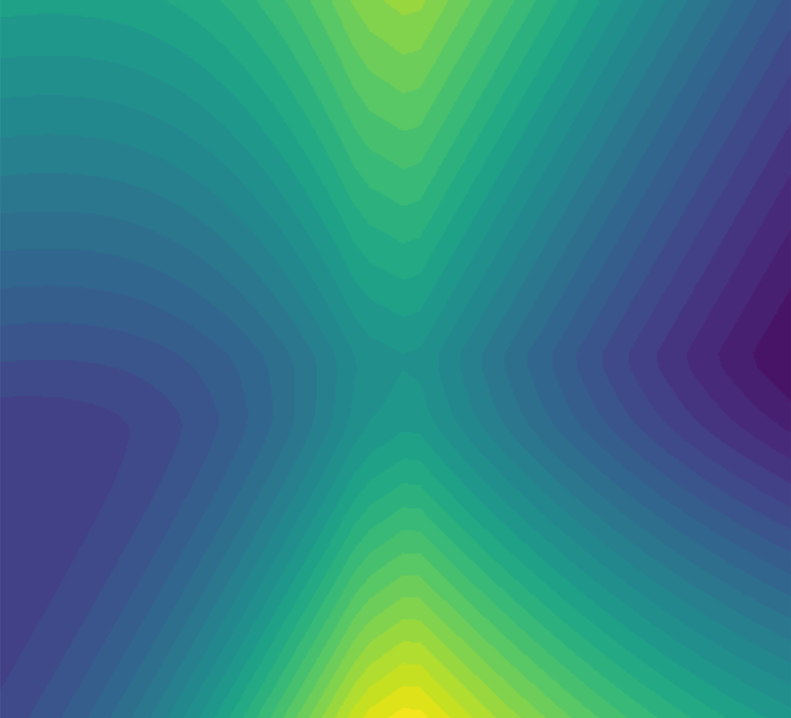
Reinforcement Learning
Dataset consists of a human demonstration that immediately died by crashing into a pipe. Dark blue values represent low loss, while the bright yellow represent high loss.
Intuitively this makes sense because the strategy that would maximize rewards (reinforcement learning) would be to do the exact opposite of what we showed it (imitation learning) since the expert died right away and got a massive negative reward.
This highlights a crucial insight: the less optimal the human demonstration is, the more RL diverges from the demonstration to find a better policy. Instead of merely replicating suboptimal actions, the RL agent learns to improve upon them.
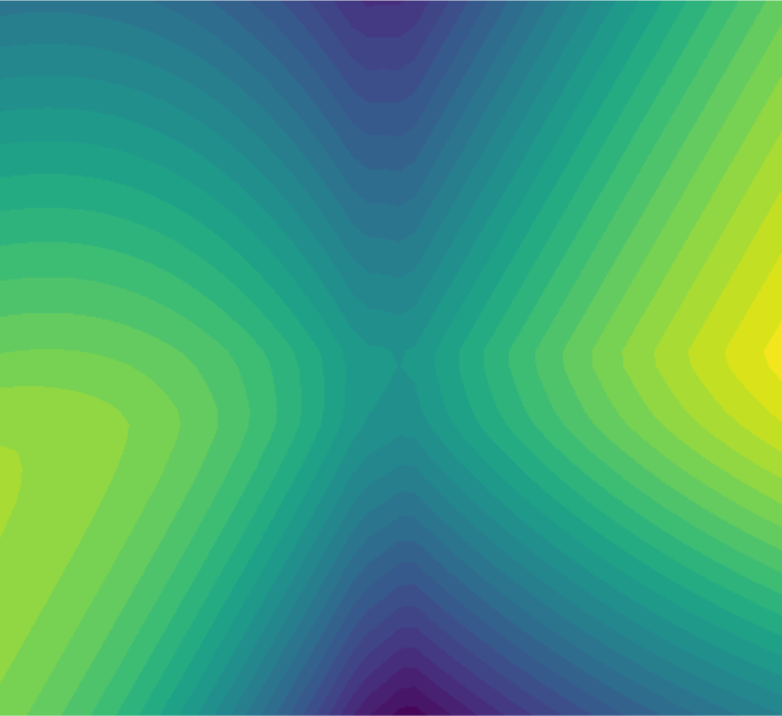
A Strong Gameplay Session
For the second part of the experiment, we played very well and we see that the result follows our intuition from the previous section.
Imitation Learning

Reinforcement Learning
Dataset consists of near-optimal human gameplay. The RL agent's loss landscape closely resembles the one derived from imitation learning.
Since the human demonstration was already highly optimal, we see that the objective of IL (copying) and RL (maximizing return) is very similar since copying the strategy would result in close-to-maximal return.
So… Should We Always Use Reinforcement Learning?
Not necessarily. While RL is powerful, it is not always the best choice. In many cases, IL can serve as a valuable method to get a “headstart”. By starting with IL, an agent can quickly acquire a reasonable policy without extensive exploration. This initial policy can then be fine-tuned using RL to further optimize performance.
Moreover, the goal of training an AI is not always to achieve superhuman performance. Sometimes, the objective is to create an AI that behaves like a human rather than learning the most optimal strategy. In such cases, imitation learning may be the preferred approach, as it focuses on replicating human-like behaviors instead of purely maximizing rewards.
Conclusion
Both imitation learning and reinforcement learning have their place in behavioral learning. Imitation learning provides a fast and efficient way to replicate expert behavior, while reinforcement learning allows for continuous improvement beyond demonstrated actions. By leveraging both methods strategically, we can develop AI agents that balance efficiency, adaptability, and human-like behavior.